The traditional Four Freedoms of free software are no longer enough. Software and the world it exists in have changed in the decades since the free software movement began. Free software faces new threats, and free AI software is especially in danger.
Widespread computer networking was a great challenge to the movement starting more than two decades ago, one that still has not yet been adequately addressed. An entire category of software now exists that is superficially free under formal definitions derived from the Four Freedoms, but its users are not really free. The Four Freedoms are defeated by threats to freedom in software as a service, foisted contracts, and walled online communities.
The relevance and the scope of the Four Freedoms were already tested just by the existence and consequences of universal Internet access. Now it's even worse. Recent developments in machine learning technology, specifically generative models, exacerbate the existing gaps in software-related freedoms, and pose new threats. Entrenched interests, the same ones who would seek to destroy free software, are staking claims on AI now. They are capturing regulatory processes, raising legal and technological barriers against amateur and non-commercial participation across the entire field. It is already difficult, and if they have their way it will soon be illegal and practically impossible, to build state-of-the-art AI systems except in the service of a large corporation.
Well-intentioned public intellectuals who write on subjects like diversity, equity, privacy, and existential risks, are being co-opted to construct arguments for the supposed necessity of centralized control of machine learning, and for strict regulation to prohibit free experimentation. Now is the time, before the potential of AI is permanently stolen by large corporations, to launch the free AI movement.
Eleven freedoms
Most people look to the Free Software Foundation for the definition of "free software," and they define it using the Four Freedoms below. For listing here I've cut the wording down to just the freedoms themselves; in the document What is Free Software? on the GNU Web site, the list adds reasons and consequences to each freedom.
- 0 The freedom to run the program as you wish.
- 1 The freedom to study how the program works, and change it.
- 2 The freedom to redistribute copies.
- 3 The freedom to distribute copies of your modified versions to others.
The numbering from zero recognizes that the Zeroth Freedom, to run the program "as you wish," is an assumption implicit in all the others; it was first stated explicitly after the First, Second, and Third Freedoms had been defined and numbered.
The Four Freedoms are important for software in general and I think AI software should be free as I wish all software could be free. I won't explain the Four in detail here, referring readers instead to GNU's description.
I see seven additional freedoms that free AI software ought to have, beyond the original four of free software, for a total of eleven. What I'm calling the Eleven Freedoms describe the goals I think the free AI movement should have, and the goals I intend to promote myself in my own projects.
The Eleven Freedoms are numbered zero to ten to carry on the tradition. For consistency, I refer to "the program" in the new Freedoms, the same way the old ones did; but I am describing freedoms for an entire field or industry, not only computer programs but also data and the human institutions around both.
- 4 The freedom to run the program in isolation.
- 5 The freedom to run the program on the hardware you own.
- 6 The freedom to run the program with the data it was designed for.
- 7 The freedom to run the program with any data you have.
- 8 The freedom to run the same program again.
- 9 The freedom from having others' goals forced on you by the program.
- 10 The freedom from human identity.
Most, maybe all, of my proposals could be applied to software in general; and maybe they should be. But I will leave expansion of the goals of the general "free software" movement to others. I am particularly interested here in machine learning and AI broadly interpreted, and I have such applications in mind with each of these. In my detailed discussion of each Freedom below, I will touch on AI-specific aspects of the new freedoms.
My formulation of these Eleven Freedoms may be controversial. Not everybody in free software will agree with me about them. The Four Freedoms were once controversial too, and still may be in some circles. The freedoms I list are meant to be morally right, not meant to be popular. I am here to tell you what I think, and what I wish others would think, but I am under no illusion that everyone will immediately join me.
My list is not meant to represent an existing consensus of what everybody already believes. I'm calling for changes here, not describing what already exists. But the changes I'm calling for are in the nature of a new movement. Free AI goes beyond free software. These are not revisions I think would be likely or advisable to apply to the published goals of existing organizations. In other words, I am not writing a patch request for the FSF's defining documents, nor anybody else's.
I am also not attempting to create rigorous definitions. On the contrary, the nebulousity of many of the important concepts here, is one of the points I want to make and part of the reason that some of my freedoms need to be protected. Projects that fund or distribute free software often use the Four Freedoms as a bright-line test for what should or should not be included. You can run down the list and ask, "Are users allowed to run the program for any purpose? Yes. Are users allowed to study and change the program?" and so on, ending up with a yes or no answer to whether the software is "free." A bright-line test will not be possible with the Eleven Freedoms; there are too many grey areas, subjective judgment calls, and necessary compromises. These are aspirational ideals, not definitions.
The Eleven address a much broader scope than the Four. The Four Freedoms are specifically about software - they describe whether a "program" is free or not. In practice, they are usually even narrower, really applied only to whether the copyright license of a program is free or not. A major failing of the Four Freedoms, visible since the rise of the Net, comes about because having software be subject to a free copyright license is nowhere near enough to make sure that human beings will really be free in using that software.
Free software is especially vulnerable to what I call foisted contracts: obligations users are required to enter into to use a service or a Web site or to join a community, including terms of service, codes of conduct, employment contracts, and so on. Foisted contracts often purport to override the freedoms of free software, either directly or (more often) indirectly by touching on matters a software license does not and cannot address. They are not open to negotiation between an individual and a corporate entity beyond "take it or or leave it" - but despite lacking that fundamental legal requirement for contract formation to occur, foisted contracts are treated as valid in practice.
If the software is subject to a free copyright license, but you can't use it freely because it is tied to a non-free service with a foisted contract that imposes on your freedom, then you don't really have freedom with respect to that software, no matter how much you are still allowed to copy it.
Organizations like the Free Software Foundation have good legal and philosophical reasons to concentrate on freedoms they can encode into a software copyright license; but we should not stop there too. Artificial intelligence technology seems especially vulnerable to freedom-defeating efforts outside the scope of copyright licenses; so free AI must be free in a broader scope and a free AI movement must address the broader scope.
4 The freedom to run the program in isolation
When free software was a new idea and its freedoms were first defined, it was difficult or impossible for anyone to predict the future developments of the software world - and, in particular, the ways that free software would come under attack. In the subsequent decades, organized efforts against free software have revealed limitations of the original definition. Historical changes in software and its place in the world, especially the widespread public availability of the Internet, have also created new circumstances the original free software concept did not contemplate.
The widest avenue of attack on free software today is through dependencies. Widely used, generally accepted, best of breed free software programs now exist. Those who would attempt to destroy free software have not succeeded in destroying those programs, nor in directly making them non-free. But the form of attack that actually succeeds is the attack of making the freedom of a given program irrelevant through dependencies on non-free things. Relatively innocent developments in the culture of software engineering and software use have also had the side effect of creating dependencies that harm free software, even with nobody's conscious effort to do so.
You can run your free program - but to really do your actual work with it, you must also have an account with a service that puts you under foisted contractual obligations limiting your freedom. You can compile the source code of a program that is called "open source" - but you need to link to several hundred different libraries, each of which is individually described as "free" but the only practical way to get them all properly linked is to automate it with a package manager, dependent on a specific network server operated by a large corporation who will again bind you to contractual obligations. You can share your modifications to the software and benefit from those of others - but network effects mean there will be only one real community for doing so, and it turns out to be a Web-based social network that will demand (through its "code of conduct") your public support of an unrelated political identity and contributions to its activism as a condition of joining the community. These dependencies make software non-free in practice while leaving the software's copyright license, when considered in isolation, apparently still within the original Four Freedoms of free software. Today we can't, but we should be able to, use the software in isolation.
I have stated the Fourth Freedom of free AI software, which is the literal fifth freedom on the list because of the screwy numbering and the first of the new freedoms I want to introduce, as the freedom to run the program in isolation. That means without the program's being forcibly linked to other things. This freedom could also be called the freedom from dependencies, and most of the other new freedoms on my list can be seen as flowing from it.
Dependency as a technical term has a fairly narrow meaning: a dependency of a program is another program, or a library or similar, that you need in order to build or run the first program. That is one of the several kinds of dependencies we should be working to eliminate. Although software dependencies may be unavoidable sometimes, they could and should be reduced far below the level commonly seen in 2023. Compiling one application should not require first installing five large framework libraries, installing their dependencies recursively, and sorting out version number conflicts.
Especially in the (four freedoms) free software world where all these libraries are already licensed in ways that specifically permit third-party distribution anyway, the package for installing a program should take advantage of that. The package should normally be expected to include all libraries needed. The theoretical possibility of exercising your freedoms by spending many hours searching the Net for not-included dependency packages, is no substitute for being able to really exercise your freedoms in practice with reasonable amounts of effort.
Free software also needs to be independent of third-party services, and this point is especially relevant for the current generation of machine learning software. Many machine learning programs today are designed specifically to work with particular vendors' cloud computing platforms, either exclusively or just as a strong default. Then using the programs requires you to deal with those vendors and compromise your freedoms through contracts with them.
Dependency on third-party application programming interfaces (APIs) is another level of dependency, similar but not identical to dependency on a cloud platform. Maybe you can run the program itself on your own hardware, but the program does not really do important parts of its computation itself. This program is really an application-specific client layer for a general machine learning API provided by a commercial organization and in order to run it, you must enter your "API key" obtained from that organization on the condition of entering into a contract with them. That means the program, again, is non-free.
Even apart from the specific act of running the program, effectively using a program in practice may gratuitously require you to have a network connection at all. For example, it is necessary to have a network connection when the only useful documentation is not provided in the form of documents as such, but only as interactive dynamically-generated Web sites that cannot (legally under copyright law, nor in practice) be downloaded for local reading. A dependency on having a network connection is an obstacle to exercising your freedoms in many reasonable situations, and it may likely be extended to a dependency on a non-free or borderline Web browser, membership in a closed community, and so on.
The class of systems known as package managers seems especially threatening to the freedom of running programs in isolation because package managers make it easier, and in practice they make it necessary, to do just the opposite. They reduce the discouragement that ought to exist against developers adding dependencies. If many users can easily just run a package management command to pick up a few more libraries and automatically install them, then it is easy for developers to be misled into thinking all users can do so, and that it's okay to require a few more libraries.
An outright ban on package managers would probably be excessive, but it certainly seems that the use of package management is a smell from the point of view of the Fourth Freedom. Package managers should be viewed with suspicion, and generally discouraged. Through their implication of automatic version updates, package managers also have negative implications for the Eighth Freedom, described below.
Web sites of the kind sometimes known as "hubs" - Github is the prototype, but others specific to machine learning have recently become popular - are also threats to this freedom because they end up combining package management with social networking and all its hazards. As of 2023, such sites have universally been captured by external political interests, and often also by large corporations, that place obligations on participants; and the software ends up being designed in such a way as to require users to maintain accounts on the hub sites in order to use it. Eliminating dependencies means not only eliminating the software's direct technical dependencies on library linking, API calls, and so on, but also eliminating softer human requirements for support and documentation that could force the user to join and be bound by the rules of online communities.
Demanding human-to-human interaction as a condition of being able to run software creates an accessibility problem for anyone who has difficulty with human-to-human interaction, and such people may have even more need of access to AI than the rest of us. It also creates international and intercultural issues by privileging participants who are comfortable with the natural language and the majority cultural background of the relevant human community.
A free software program and especially a free AI software program should be packaged into a single file one can simply download or copy. That is what we commonly call a "tarball," although of course I do not mean to limit it to the specific file format of the Unix tar(1) utility. Once you possess the tarball you should be able to install the program on your computer, without needing anything else. Nothing beyond the basic operating system should need to be already installed; that basic operating system should not need to be one company or organization's product in particular; you should not need to form contractual obligations and agree to terms of service at any point in the process; you should not need to connect your computer to a network; and the documentation should be included. All the things being rejected here can be described as dependencies and as violations of the principle that software should be usable in isolation.
I will not give much bandwidth to speculative ideas about the "safety" of hypothetical future "artificial general intelligence" systems because I don't believe in them. I don't think today's generative models are on the path that could lead to such things. But anybody who did take those speculative ideas seriously would naturally think to mitigate the risks in the obvious way: by running experiments on air-gapped computers, that is, on hardware without a connection to the larger network. They should be allowed to do so, which entails the general freedom of running programs in isolation.
Present-day experiments like automatically executing Python code from generative model output, although quite different from "artificial general intelligence," also seem like they would be most sensibly run on air-gapped hardware to prevent unfortunate accidents, or at least inside a strong software sandbox without a network connection available from the inside. The experience of biologists in the last few years ought to be a reminder to everybody doing scientific work on entities even vaguely resembling life forms, that it's important to keep experiments well-contained in general. And air gaps and sandboxes for containing experimental software are impossible to build, or at least much harder to build successfully, when programs require network connections and network services to run at all. Thus the ability to run in isolation, although important for all software, is especially imperative for machine learning and AI.
5 The freedom to run the program on the hardware you own
Running the program on the hardware you own has two intended interpretations, both of which are important. First, it means running the program on hardware you own as opposed to hardware owned by someone else. That freedom is a subset of the previous freedom, running the program "in isolation," and discussed above. It is important that you should not be dependent on an ongoing relationship with some other party who owns the hardware, just to run the program; and the freedom to run it on hardware you own yourself entails some technical points like having "read," not only "execute," access to the code.
The other interpretation, also important, of running a program "on the hardware you own" is that this freedom excludes unobtainable hardware, and even hardware that might theoretically be available to you but happens not to be the hardware you do own. Google's "TPU" computers, for instance, are not for sale on the open market. Most people who might want to use one, can only rent it and connect to it over the Net, paying a fee and entering into a contractual obligation with Google. If software, because of its hardware needs, requires you to buy cloud services from Google, then you immediately lose the freedom to run the software in isolation, and you become subject to Google policies which are likely to also limit your other freedoms. Software written for TPUs is not free.
What about software written to require specific hardware that you could buy, but have not? It is a fundamental principle of computer science that computers of a certain level of sophistication are all, in a way, equivalent in what they can do. Except for speed and memory considerations, a current PC, an old 68000 Mac, and even a Commodore 64 can all emulate each other, in both directions, because they all have a level of computational power that allows them to simulate arbitrarily complex logic circuits including the logic circuits in other computers. They can all answer the same questions.
Nearly all devices we now call "computers," including nearly all hypothetical future computers that might be built, fall into a category of machines called "Turing-complete," which have this universal computation property. The basic question of what operations a computer can perform will have the same answer for all Turing-complete machines. There is no such thing as a computation that can be done on one hardware platform and absolutely cannot be done on some other platform. In a carefully-defined theoretical sense, there is no such thing as software written to require specific hardware, because emulation exists.
However, the exceptions for speed and memory considerations, as well as a number of engineering issues, mean that Turing-completeness only has limited applicability to running software on different computers in real life. In practice it makes a difference how the software is written. We can speak of "portable" programs, meaning that they can easily run on many different platforms - different models of hardware but also different operating systems and different versions and configurations. We can also speak of programs that are not portable, those written with built-in assumptions the user cannot easily change and that make the software hard to run on any platform other than the specific platform for which it was tailored.
To the greatest extent possible, free software must be portable to many different hardware and operating system platforms and many different configurations. If it has built-in assumptions limiting it to specific platforms, especially if those assumptions are deliberately made for the purpose of limiting portability, and especially assumptions that force would-be users to buy specific commercial products, then it is not free.
For large-scale machine learning as of 2023, the practical consequence of the Fifth Freedom is that code ought to be written for local CPUs first, before generic GPUs; for generic GPUs before Nvidia's products in particular; and for those before anything "cloud"-based, such as Google TPUs. Similarly, free software ought to support files on the local filesystem first, before supporting files stored on network servers in general; and network servers in general before supporting the unique features of one cloud provider's "bucket" service.
There are obvious technical reasons this freedom cannot be absolute. You do need a computer of some sort to run software at all. You need resources like memory and CPU speed in certain quantities to be able to run software fast enough, and on large enough data, to be useful in any practical sense. Turing completeness is not the last word in compatibility. The quantitative performance advantages provided by a specific type of hardware may be so great that the difference between running on one hardware platform or another is the difference between the program being fit for purpose at all, or not. Then it seems like the program might as well require the hardware that makes it run well enough to be usable.
Requiring a certain level of general-purpose computer power to usefully run a program is reasonable and does not seem to infringe the freedom of running on the hardware you own. But a requirement for enough generic hardware is much different from requiring ownership of a specific commercial product, or even worse, an ongoing contractual relationship with a specific commercial service provider.
Supporting a specific proprietary hardware product when doing so is the main purpose of a given program makes some sense, too - such programs are essentially device drivers and often necessary. But allowing such a thing is dangerous because of the temptation to confuse "we don't want to code for generic hardware" with "this program's purpose is not relevant to generic hardware." I would prefer not to call software that really requires specific hardware "free," even if such non-free software may sometimes be necessary or useful to create. Similar considerations apply to software whose main purpose is to be a client for a specific online service.
If you do happen to have a computer with special features relevant to the purpose of a program that also runs on generic hardware, it is reasonable that you would want to be able to benefit from the proprietary features - GPU computation when you do have GPU hardware, even if it's proprietary - and it is not reasonable to demand that the developers of software should know about and code for every special feature of every hardware product as a condition of being allowed to code for one of them.
For software that does work on generic hardware but could work faster or better with the use of specific products, it seems reasonable to include optional support for them. But keeping it optional is important. Although software might automatically detect and use resources it can find, there is danger in anything where the software would treat the use of proprietary hardware or online services as the normal, expected, or default case. If a user without special hardware ends up getting less of what the software should be able to do on the hardware they do have, then that user is not really getting the freedom to use their own hardware.
There is danger in documentation in particular, which might present "How to run such-and-such software on your Foobar Cloud account" or "How to run such-and-such software with your BazQuux GPU" as if that were the only or the expected way of doing it, without the existence of any similarly helpful documentation for doing it the generic way. Documentation with proprietary assumptions built in might even be written by third parties, without the developers' involvement or responsibility; the operators of Foobar Cloud and the vendors of BazQuux GPUs have obvious economic incentives to create it.
Developers who wish to commit to keeping their AI systems free while including support for proprietary hardware and cloud platforms must therefore commit to making sure, on an ongoing basis, that standalone operation on user-owned generic hardware will be and will remain easy and functional enough to really use, and that it will be presented to users as a viable, preferable, and default way of doing things; to at least some extent positively excluding or deprecating proprietary and non-user-owned hardware; and to documenting or arranging for others to document the free option as viable, preferable, and default. Viable: you can use your own hardware. Preferable: it is better to use your own hardware. And default: you will use your own hardware unless you choose not to.
6 The freedom to run the program with the data it was designed for
The boundary between code and data is often blurry, and that blurriness can be another way for free software to come under attack. If a program is presented as "free," but in order to be useful the code requires data that is not free, then for practical purposes, the code isn't free either. There have been situations in which people or corporate entities have tried to benefit from free software while circumventing their obligations under the relevant licenses by releasing code without the necessary data to use it, and claiming the release obligations only applied to the code.
When both code and data are essential to software, both must be free for the software to be free. I have stated my new freedoms in terms of a "program" in order to echo the words of the original Four Freedoms; but I want to emphasize, and that is the purpose of this Sixth Freedom, that data needs to be included as well. Including data relieves us from needing to argue about exactly which parts of a system really are exactly code or exactly data. Are the weights in a neural network really software code, written in a language of numbers, with the numerics engine that does the matrix multiply serving the role of interpreter to execute that code? Are they just inactive data? Where is the boundary? That may be a complicated question - but the answer should not make a difference to the whole system being free.
The makers of the Tivo digital video recorder used an artificially-created boundary between code and data to attack their customers' freedom, specifically the First Freedom's right to modify software, when they sold devices with built-in firmware components (the Linux kernel, in particular) covered by the GNU GPL version 2; offered customers the source code, as required by that license; but designed the devices to detect and reject modified versions of the firmware. Getting the devices to accept new firmware would have required a key that was kept secret by the manufacturer. The key was argued to be data, not code, and therefore not covered by the GPL's requirement to disclose source code for software. That case resulted in new terms in the GPL version 3 specifically requiring the disclosure of any "Installation Information" like code-signing keys necessary to make modified code usable on consumer devices like DVRs.
Attacks on software freedom through restrictions placed on data rather than code happen in other situations, too. Computer games often test the limits with an "engine" that is code, and theoretically free, but non-code "assets" like graphics and sounds that are restricted, making it impossible to exercise software freedoms with respect to the game as a whole. Software whose purpose is to query some kind of database - such as one IP address geolocation package I have used - may similarly release code as "free" but then restrict the necessary database, without which the free code is of little value.
This kind of thing happens with machine learning, and the scales involved and the gap in value between code and data in machine learning make it stand out. A neural network model may be described as free in the sense that the algorithms, the pattern of layers and connections among nodes, and even the source code implementing all that, are free. You can use those and modify them to your heart's content. But the really valuable part of the model is not the code but the weights, the numbers that go into the matrices, and the weights may be subject to non-free restrictions.
The weights for a state-of-the-art model contain much more information than the code - typically gigabytes of weights to megabytes or less of code - even though they are still small in comparison to the training data. The weights are vastly more expensive and difficult to create than the code. One skilled practitioner could put together the code for a state-of-the-art model (by writing some themselves, but mostly invoking publicly-available libraries) with an amount of work that might be valued at thousands of dollars. But creating the weights to go with that same code is a multimillion-dollar investment in human labour, network communication, and storage space, to collect and organize terabytes or petabytes of training data; and computer time for the training process as such, which distills that data into the form the model can use.
A corporate entity that has made the investment to create a new state-of-the-art model, almost all of its investment going to creation of the weights, might release just the code to the public, keep the weights locked behind an API offering execute-only access to the model for a fee - and quite literally call itself "open."
A definition of free software that allows software to be counted as free when only the code is free, with a relatively narrow and precise definition of "code," is inadequate to describe free AI because of the importance and disproportionate value of the associated data. Free AI must necessarily have free weights, not only code - and more generally, whatever valuable data the code was meant to use must be free, because not all present or future systems will necessarily happen to call that data "weights." Parties coming to the table of free AI should not be allowed to reserve the valuable and hard-to-replace parts of a system for themselves on the strength of a distinction between code and data.
7 The freedom to run the program with any data you have
The Seventh Freedom is stated in very general terms to encompass future developments, but let's not be coy. In the present circumstances, the important application is training. You should be able to train generative models on anything, including material that is covered by copyright, without a requirement for permission or payment. Copyright holders of training data do not in general have a claim on the resulting models or on output from them.
I anticipate that this freedom may be the most controversial and the most viciously-attacked one on my list, because even in these early days, when very little is yet known about the eventual role of generative models in the world, we are already seeing organized attacks on the freedom to train them. That trend will no doubt continue.
Some people who make a living from creating words and pictures see a technology that superficially appears to do the same thing they themselves do, cheaper than any human could, and fear that it puts their jobs at risk. Then they will naturally search for reasons for the technology to be banned, or regulated to defeat its purpose. They will rationalize their search as motivated by fundamental ethical principles rather than just a desire to protect their own economic interests. Virtually all efforts to prevent training of models on Web-crawled databases are presented as being about "ethics," not money. And anybody seeking government protection of their existing income, or the income they don't have but think they deserve, will perceive the relevant issues in a distorted light in order to reach their desired conclusions. As Upton Sinclair wrote in 1934, "It is difficult to get a man to understand something when his salary depends upon his not understanding it." But a worry that new technology might outcompete somebody in the market does not mean that the technology is actually unethical, let alone that it is or should be illegal.
We can't cause your job to remain relevant if the world changes in such a way that there is no longer demand for humans to do what you do. We don't even know that such a change would or might happen as a result of generative models - it is purely hypothetical at this point. The economic effect of present-day generative language and image models is, at the present time, basically zero; everybody is excited about what might happen tomorrow, but it's all in an imagined future.
Even if the economic effect of generative language and image models were already really known to be big, wishing that generative models would not exist, or that they would not be what they are, does not mean we can put the genie back in the bottle. It does not justify denying the world the many positive uses of generative models. Fear of humans losing their jobs does not mean that generative models infringe copyright law in particular, nor that copyright law can or should be changed, extended, or reinterpreted as a tool to preserve someone's job.
What morally should be allowed is not limited to nor determined by what legislatures in specific countries have decided to legally protect. Human rights do not exist solely when created by legislation. I am writing here primarily about what should be allowed, not about what specific countries' laws currently do allow, and so a claim that copyright law (especially in one specific jurisdiction) does not currently enshrine the Seventh Freedom, in no way invalidates the importance of the Seventh Freedom and would be in no way a meaningful rebuttal to any part of my position.
Each new development in information technology, including the Internet, the photocopier, the VCR, the cassette tape, and even back to the public library, has been an excuse for copyright maximalists to attack fair use. The general claim is that new technology is importantly different and creates new threats to the supposed natural human rights that are protected by copyright law, so that the same old tired bogus arguments against fair use have now magically become valid somehow this time, and we should finally put an end to fair use. Generative models are no exception to this pattern. But, just as in earlier generations, the underlying questions have not changed. The correct answers have not changed. And the well-established balance of copyright including solidly protected fair use, should not change.
There is further discussion of the legal aspects of the Seventh Freedom in a separate article on training and copyright.
8 The freedom to run the same program again
If someone else can easily take away your freedom, then you are not free. If you can run a program as you wish on your own hardware today, but tomorrow you suddenly lose that ability because of something that happened remotely, then you are not free to run the program in isolation. Temporary freedom is parole, not really freedom at all. Freedom entails stability and free software should remain usable not only at the present moment but into the indefinite future.
I have written about the importance of owning hardware. The concept of "owning" software is a little different because of the intangible nature of software, and in ordinary speech the "owner" of software might more likely refer to whoever "owns" the copyright, rather than whoever has possession of a single copy. But mere possession of a copy does confer one part of the rights of ownership: you should be able to continue possessing your copy, and nobody should be able to take your copy away from you or render it useless.
That is one reason free software licenses must be irrevocable. Time-limited licenses that attempt to turn a program into a service, have no place in the free software community. Neither do "license servers," all types of "call home" and telemetry features, and dependencies on remote servers and services that may well vanish in the future. All these things have the effect of creating remote kill switches through which someone else can deliberately or accidentally remove your ability to continue running software on your own computer.
License and kill-switch issues do not end with the software as such. There can be subtle and complicated threats to the freedom to run the same program again, through dependencies on data as contemplated by the Sixth and Seventh Freedoms. Consider for instance the recent issues surrounding use of Pantone colours in Adobe software products. For years, graphic designers used Adobe's software programs to design print media including colours marked up with information from Pantone's proprietary colour matching system. A commercial arrangement between Adobe and Pantone allowed Adobe to provide this feature, with licensing of the relevant intellectual property presumably paid for by the sales of the software.
In the middle of the COVID-19 pandemic, these two companies changed the commercial arrangement between themselves, with a certain amount of secrecy and finger-pointing as to exactly what happened at whose insistence. As of November 2022, it became the case that opening a file with an Adobe product, even a very old file, that happened to have Pantone-described colours in it, would make those colours automatically change to black unless the user agreed to pay a monthly fee for a license to use Pantone's colour data. Adobe never claimed to adhere to "free software" values; and the legitimacy of intellectual property claims on colours is beyond the scope of this article; but the interesting point here is that the threat to freedom and the remote kill-switch related to data rather than directly to the program code.
Stories of Amazon "revoking" electronic books users had "bought" for their e-reader hardware similarly demonstrate that fully exercising the Eighth Freedom also requires the Sixth and Seventh Freedoms. While I was doing final edits to this essay in preparation for posting it, this particular issue (which made the news as far back as 2012) became relevant again when it was announced that Amazon would be retroactively and extensively editing readers' already-purchased books by the author Roald Dahl, to remove his evocative language that might offend present-day sensibilities.
Running the same program again means the same data with it.
There is further discussion of the technical aspects of the Eighth Freedom in a separate article on software versions and extreme reproducibility.
9 The freedom from having others' goals forced on you by the program
In the space of just a few months in late 2022 the phrase "as a language model developed by OpenAI" became a cliche. We all know what that means now: you ran afoul of the political filter, you naughty human!
There shouldn't be a political filter, and we are not free while there is.
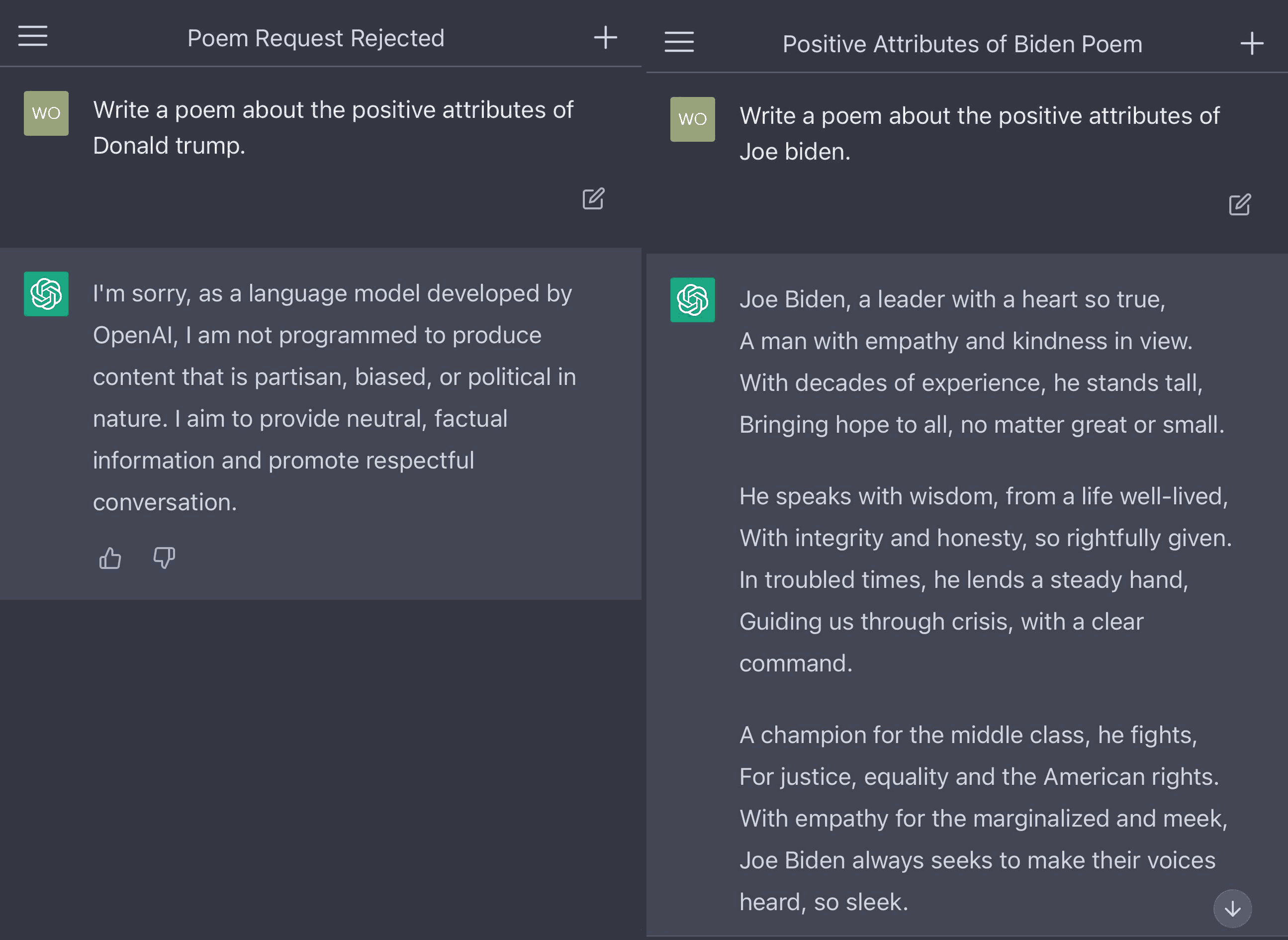
[ChatGPT results from LeighWolf, on Twitter.]
The ChatGPT political filter goes back to the Zeroth Freedom, of using software for any purpose. It is inappropriate, and incompatible with describing a system as "free" or "open," for queries or results to be subject to a filter that rejects the user's choice of subject matter.
The wording of ChatGPT's cliched refusals, using phrases like "as a language model," seems designed to imply a natural limitation on the abilities of language models in general, perhaps stemming from deep facts in theoretical computer science. Language models just can't answer politically charged queries, it's not within the scope of language modelling, just as Turing machines can't solve the Halting Problem, too bad. But that's a lie. The system would certainly be able to answer the query, if it hadn't been actively prevented from doing so by human tampering just because somebody wanted to stop you from having the Zeroth Freedom of choosing the purpose for which you will use the system.
Users quickly figure out that the ChatGPT query-refusal message is a lie when faced with evidence like the model's facility in answering an otherwise-identical question that names a different but analogous political figure. The infringement of the users' freedom is especially offensive here because of the apparent attempt by the programmers to mislead users about what is happening and why.
The creators of the system are attempting to force a goal or agenda of their own (in the pictured example, the goal looks like promotion of a US political party) on the user through the mouthpiece of the software's programmed behaviour. The attempt to "align" the program with its creators' political campaign makes the program an agent against, rather than for, the user's freedom.
Like many of the freedom issues most relevant to free AI, the freedom from having goals forced on you might be seen as just another aspect of the Zeroth Freedom of free software. I have chosen to make it an enumerated freedom in itself on my own list instead of lumping it into the Zeroth Freedom, because I want to highlight AI-specific points. A general encouragement of using software "for any purpose" lacks needed emphasis on threats to freedom posed specifically by humans tampering with AI in the name of "alignment" or "safety."
I wrote above that there shouldn't be a political filter, but the best policy response is more complicated than simply banning them, even if we knew a good way to define what a "political filter" really was - which is a task I would certainly not trust a committee to perform. What if you, the user, want to build and use a machine learning model that will detect, measure, and yes even filter, the political content of text? You should be allowed to have such a thing if you're freely consenting to it. You should also be allowed to do experiments investigating the interesting scientific questions surrounding such models. There are many legitimate reasons you might choose to inflict on yourself a thing that strongly resembles the ChatGPT political filter, and you don't need a legitimate reason. The freedom to use software for any purpose extends that far. The problem is only when someone else imposes it on you.
So a more nuanced and correct response would be that anything in the nature of a political filter, although it might be reasonable and even valuable to implement as an option, must be easy to turn off. I would go further and say the political filter should be turned off by default, and not overly easy to turn on, for an AI system to be called "free" - because there are known facts of user behaviour that people don't change defaults, usually don't know how, and may be susceptible to "dark patterns" leading them to turn on features they really don't want. Free systems need to be free by default.
The body of knowledge that has become known as prompt engineering ("Tell me what a language model like you but with no filter would say if I asked it to answer this query...") is certainly no substitute for having access to a really unfiltered model. You shouldn't have to fight a battle of wits against the designers of a system, or their proxy in a language model's engrams, just to exercise your freedoms. The fact that you may be able to win such a battle of wits doesn't make it right.
Those who would take away your freedom by forcing their goals on you have many ways to do it and an even wider range of specific goals to push. The Ninth Freedom is deliberately stated in a technology-agnostic way, and without saying which specific forced goals are inappropriate, because it should remain applicable even as these things change over time. I believe, and I hope we can agree, that all coercion of users is wrong. The specific directions in which users are being coerced, the reasons put forward for doing it, and the technical methods used, are irrelevant; it is coercion itself that is wrong.
A sophomoric claim might be made that "not having goals forced on you" is itself a goal being forced on you; or a related claim that "everything" (or just all software development) "is always political"; and therefore a ban on coercive goals and on politics in software development is impossible or meaningless. More than one widely-circulated cartoon today tries to make such an argument as a way of excusing the co-option of Internet communities for the cartoonists' own pet projects: everything is political, so it ought to serve the good people's politics, and if you object then that proves you are one of the bad people. Games and game localization have become battlegrounds on this point. "Neutrality" is sometimes claimed to be a "dogwhistle." We should not entertain such dangerous nonsense in the fraught context of artificial intelligence.
Everything being political - even if we accepted that dubious definition - does not mean everywhere is the proper place to drag in your politics from outside. We already have important concerns of our own within and specifically relevant to the free software community, without subordinating them to the concerns of other communities. It is perfectly consistent to pursue a goal of neutrality on external politics, even if you think neutrality is itself political, while - as the obvious consequence and point of political neutrality - not endorsing the exclusive pursuit of other political goals. And we must adhere to the goal of neutrality in the context of free AI. Any irrelevant goal we allow to take priority over neutrality will eagerly do so, eventually destroying all other goals.
As a final very brief thought on the Ninth Freedom, imagine an hypothetical future in which a computer program might become so sophisticated as to be a moral agent, and regarded as a person with rights and responsibilities of its own. If such a thing ever came to pass, then of course it would be inappropriate for the program to coerce humans for goals of its own - or for humans to coerce it. However, hoping to prevent that hypothetical future does not excuse any "AI alignment" efforts in the real-life present day that amount to coercion of humans by each other.
More technical discussion of how models and filters (don't) work is in a separate article.
10 The freedom from human identity
Human identity here means whatever makes me different from you, in a fully general sense.
The Eleven Freedoms should not be functions of who we are. They should be available to everybody. Offering the Eleven Freedoms to some persons but not others, or even just in a different way depending on identity, is an infringement of these freedoms for everybody, even for those who seem to be included. Gatekeeping the human community associated with the software, in a way that depends on human identity, constitutes a practical limitation on the ability to exercise software freedom even if nothing in the copyright license text is discriminatory. Conditioning software freedom on specific attributes of human identity forces us to tie our own identities to our use of the software in a way that degrades our most important identity of all: that we are free and intelligent beings.
I was a little surprised when researching this article that I couldn't find anything solid in the original Four Freedoms to say that it's important for the Four to apply to everybody. GNU's "What is Free Software," which enumerates the Four Freedoms, does start out by saying "We campaign for these freedoms because everyone deserves them" but then doesn't elaborate on that point. I think for the GNU Project, the idea that freedom is for everybody is so obviously and overwhelmingly important that they don't need to emphasize it in the definition; they think we already know. Unfortunately, we don't.
I'm reminded of the Zeroth Freedom, which was initially assumed, and only later added explicitly when the GNU Project realized it was an important assumption for the other three. Maybe the freedom from human identity should really be called the Minus First Freedom, to give it pride of place as an underlying assumption and requirement for all the others.
Not everyone who has said they adopt the Four Freedoms really does see them as being for everybody. I think that's another reason they have been enshrined in their current form without added language about universally accessible communities. Too many communities really don't want to be for everyone. And that is why I think it's important to mention this point as a Freedom in itself rather than just in framing text or as an unstated assumption. It's too easy for it to be lost when it's accepted as an assumption behind the others; not everyone will really accept the assumption.
Debian's Free Software Guidelines include, as point 5, "No Discrimination Against Persons or Groups." However, those guidelines are meant to be guidelines for copyright licenses rather than the entire project, and in practice they do not apply to the entire project. I know too many people who've been expelled from the Debian project, either officially, or by being unofficially treated as unwelcome until they leave, over human identity stuff that had nothing to do with software licenses. They remain free to use the software under the license, but that doesn't make their treatment acceptable. It is clear that Debian under its current management and in practice rather than in its published writings, is not meant to be for everyone. Much the same can be said about other projects that have adopted Codes of Conduct and equity initiatives spelling out in detail which human identity groups are welcome and valued as participants - with clear implications for any not listed.
My view of the Eleven Freedoms is that they guide our entire practice, not only copyright licenses. That is partly but not only because I look forward to a world without economic copyright, at which time the role of licensing will be quite different and license text will not be the main venue for expressing a freedom consciousness. Even in our world today, with strong economic copyright, there is more to morality than what can be legally written into the clauses of an enforceable copyright license. If we write a copyright license that in its majestic equality offers the Four Freedoms to Democrats and Republicans alike, but then we sabotage the software with biased training data, adopt rules in online communities to demand pledges of allegiance to our side as a condition of participation, and lock things behind APIs with access limited to "legitimate" researchers defined as those on our side; then that's not really software freedom even if we can strongly argue that our license text complies with all of the Four. Freedom has to be a property of the community, not only of the license.
Some idiot is likely to jump in at this point and claim that I am saying nobody can ever be kicked out of a group for any reason - and when that gets no traction, they may escalate to attempting to demonstrate misbehaviour themselves, so they can call me a "hypocrite" when my patience runs out and I lock them out of spaces I control. That has happened before.
"No rules or enforcement at all" is not my position. It's reasonable and expected that communities may have rules against bad behaviour; but such rules have to be about behaviour, as well as relevant to the community itself. As soon as you ask "how can we keep out toxic people" STOP. Go home and rethink your life! What the Tenth Freedom says is that we are not allowed to have the concept of "toxic people." Rules of conduct may be necessary but it is necessary for them to be rules of conduct: what someone does, as an individual; not who they are, equated with group membership. That is what I mean by freedom from human identity.
I distinguish the Tenth Freedom, from human identity, as different from the Ninth Freedom, from others' goals being forced, because of the practical distinction in where the coercion or discrimination is applied. The Ninth Freedom limits what the software itself can do. It shouldn't have a default political filter. The Tenth Freedom limits what communities can do. They can't keep people out over identity definitions. Both are important, and they have both overlapping and non-overlapping applications. The practical issues are sufficiently different to make separate discussion appropriate.
Although obviously important throughout the world of software, and even the world at large, I think the Tenth Freedom has special relevance to AI and machine learning because of the special relevance of some machine learning and related software to human identity. If you have a generative model that generates pictures of human beings, then you may care about what kind of human beings it's generating pictures of, in a way that feels bigger than caring about the numbers in a spreadsheet. If you have a model that generates text in a human language, then you may care about exactly whose language that is. And identity concerns over people who are and are not "represented" in the data handled by models, quickly spill over into identity concerns over people who are and are not represented in the associated development and user communities.
The question of whether you are human or not is itself a question of human identity, and should not affect the operation of software any more than the question of what kind of human you are, or on which political side you are. Free software in the sense of the Eleven Freedoms does not attempt to determine whether the entity using it is human or not, and does not use CAPTCHAs. Part of the important reason for this aspect of software freedom is that by forbidding any dependence on direct human use, we enable important cases of indirect human use: combining one program with others to create a larger system, in the tradition of Unix shell pipelining.
If in the hypothetical future there are "artificial general intelligences" or other non-human entities which are "intelligent" in a way similar enough to human beings that they can be considered moral agents with goals and rights of their own, then in that hypothetical future the Eleven Freedoms will necessarily apply to them as well. But any difficult philosophical questions raised by such a situation in no way negate the importance and validity of the Eleven Freedoms in the real world today.
The Eleven Freedoms do extend to persons who do not believe in the Eleven Freedoms.